
Name: Anshuman Sharma
Profile: Data Engineer | Data Scientist | Data Analyst | Lean Six Sigma Green Belt | Top Computer Science Voice (LinkedIn)
Email: anshums3@uci.edu
Current Location: Sunnyvale, California
Present Position: Software Engineer - Large Language Models
Libraries and Tools
Programming
Python, R, SQL, Shell Scripting
Frameworks & Packages
Apache Airflow, Spark, Data Warehousing (Redshift, Snowflake, SAP BW), Pandas, Numpy, Docker, Hadoop, Git, NoSQL, Apache Kafka, Cassandra, Tableau, Power BI, Looker, Look ML, AWS, Azure.
Statistical Modeling
Linear, Logistic & Multivariate Regression, Hypothesis Testing, Chi-Squared tests, Bayesian Methods, Time Series
Other
Project Management (Agile), Stakeholder Communication, JIRA for Task Management, A/B Testing.
About me
I am a Data Professional with an MS in Data Science with around 2 years of industry experience specializing in Data Engineering, Data Science and Data Analysis. I am Proficient in ML, Statistics, and adept at building and integrating data solutions, including real-time analytics and reporting. Lean Six Sigma Green Belt certified, with a track record of driving efficiency and quality improvement initiatives.
Professional Experience
Visceral.ai : Machine Learning Engineer
Feb, 2024 - Present
- Implemented an LLM auto-parser using Hermes Theta2 (LLaMA 3) on Modal, reducing survey building time by 95%.
- Developed an application for report generation across the platform, utilizing FastAPI to interface seamlessly with Hermes.
- Engineered automated plot generation to visualize underlying data for analysis and presentation.
- Designed and deployed a Retrieval-Augmented Generation (RAG) system using LLaMA 3.1, containerizing it with Docker for efficient deployment on client systems.
- Created a Chroma DB database to support the RAG system, incorporating annotations to improve response accuracy and context.
- Designed and developed consumer data access, deletion, and opt-out mechanisms, ensuring adherence to CCPA and GDPR requirements.
- Established a PostgreSQL database to initiate data collection for the Reinforcement Learning with Human Feedback (RLHF) pipeline.
- Set up evaluation metrics for Hermes Theta2, monitoring improvements in our RLHF-enhanced version of the model.
- Implemented and deployed an auto-classifier API on AWS Lambda, enabling scalable and efficient classification.
Research Assistant (UCI)
Feb, 2024 - Present
- Conducting research in data-intensive computing for collaborative data analytics at scale.
- Working closely with the research team at Donald Bren Hall to develop and implement web-based interactive workflows
- Collaborating with team members to analyze data and draw meaningful insights.
City of Irvine - Machine Learning Engineer for Capstone Project
Sep, 2023 - Dec,2023
- Developed an LLM-powered chatbot using Flask, React, and Llama2, achieving a 97% reduction in time to find contract details.
- Optimized a 1M+ document dataset with the Llama Index and fine-tuned the Llama2 model via prompt engineering.
- Dockerized the application for consistency and portability, and orchestrated its deployment using Kubernetes.
- Architected a CI/CD pipeline with monitoring and auto-retraining for long-term Chatbot efficacy.
Dell Technologies - Data Engineer Intern
Jun, 2023 - Aug,2023
- Uncovered manual reporting inefficiencies via 50+ stakeholder interviews. Derived actionable KPIs for performance improvement.
- Streamlined reporting for Marketing team (FMMs), saving over 5,000 hours annually, and an additional 10,000 hours in the PAN ISG initiative.
- Developed and deployed a data integration framework that consolidated data from 6+ sources into a warehouse (Azure Synapse Analytics).
- Spearheaded the integration of Apache Airflow, enabling automated and scalable data orchestration for the data platform.
Accenture - Data Engineer
Oct, 2020 - Jul, 2022
Electrolux E-commerce Search Optimization
- Developed a hybrid recommendation system using collaborative filtering and content-based filtering, leading to a 12% conversion lift.
- Built real-time product search pipelines in Python with Apache Spark for efficient processing, enabling up-to-date search results and improved user experience.
- Built data pipelines on AWS Glue to ingest & transform millions of daily customer events (purchases, demographics, browsing), enabling real-time recommendations & search filtering.
- Implemented Airflow logging, achieving 20% faster troubleshooting and error identification for data pipelines.
Data Modeling and Optimization
- Designed dimensional data models in SAP BW on HANA, integrating customer & sales data for efficient analysis.
- Optimized data pipelines, achieving a 20% reduction in North American data transfer delays.
- Led a team of 5 to achieve a 98% on-time delivery rate for critical BI reports, exceeding SLA benchmarks.
- Owned the data pipeline lifecycle, ensuring rigorous testing, zero-downtime deployments, and timely delivery of critical BI reports.
Samsung R&D - Data Engineer Intern
Feb, 2020 - April, 2020
- Automated 90% of manual TV testing workload with Robot Framework, saving an estimated 200 man-hours per week.
- Built a real-time data ingestion system using Apache Kafka to capture and process test logs, enabling the generation of reports with Grafana.




Projects
Design is not what it looks like and feels like, design is how it works - Steve Jobs

Development
ETL Pipeline - Cassandra DB
Transforming raw event data into actionable insights using an ETL pipeline and Apache Cassandra queries for efficient data preprocessing and analysis of music app history.
Development
ChatMind LLM
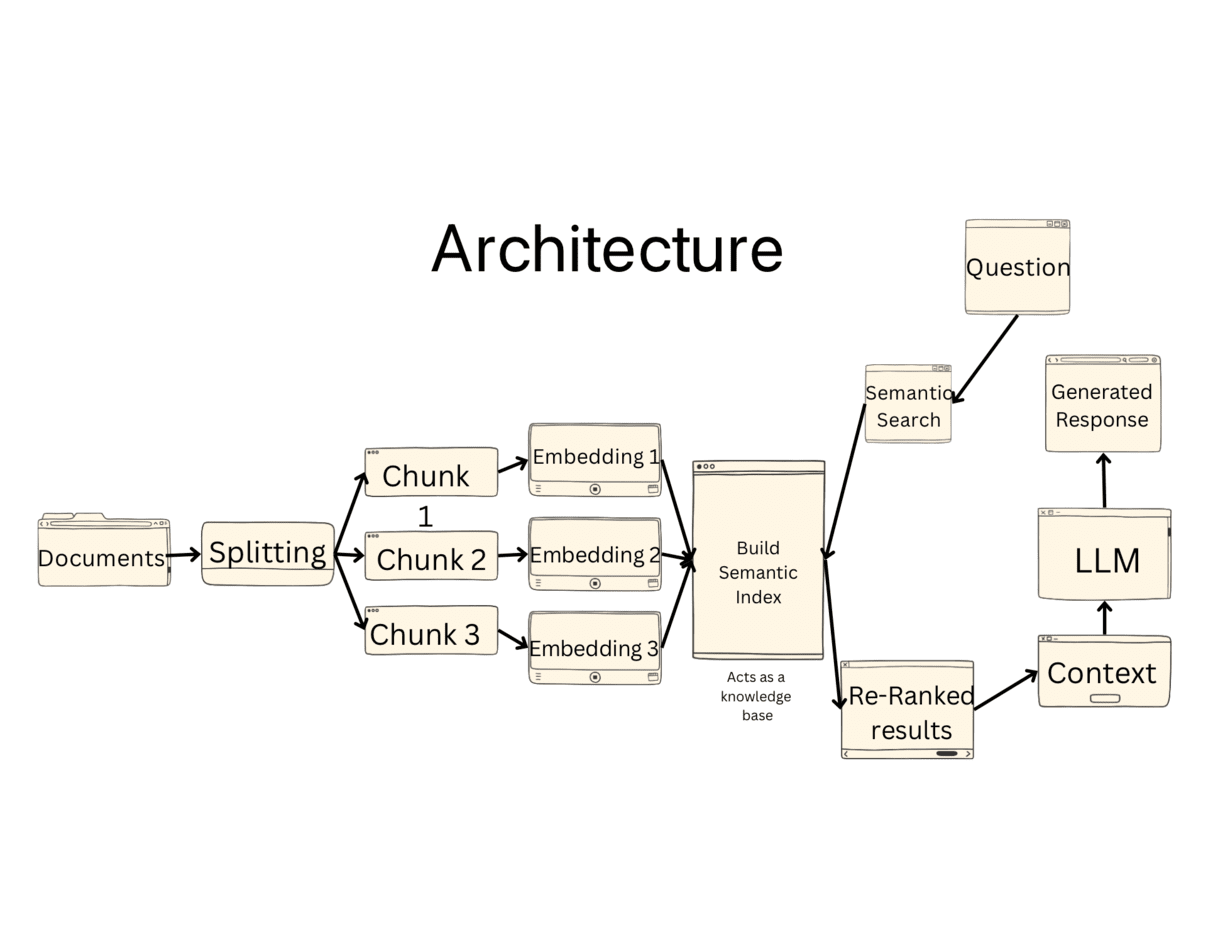
Addressing file management inefficiencies for the City of Irvine, this Capstone Project employs an internal chatbot powered by generative AI technology (LLAMA2), outlined in a comprehensive final presentation.
Development
ETL Pipeline for Music Streaming
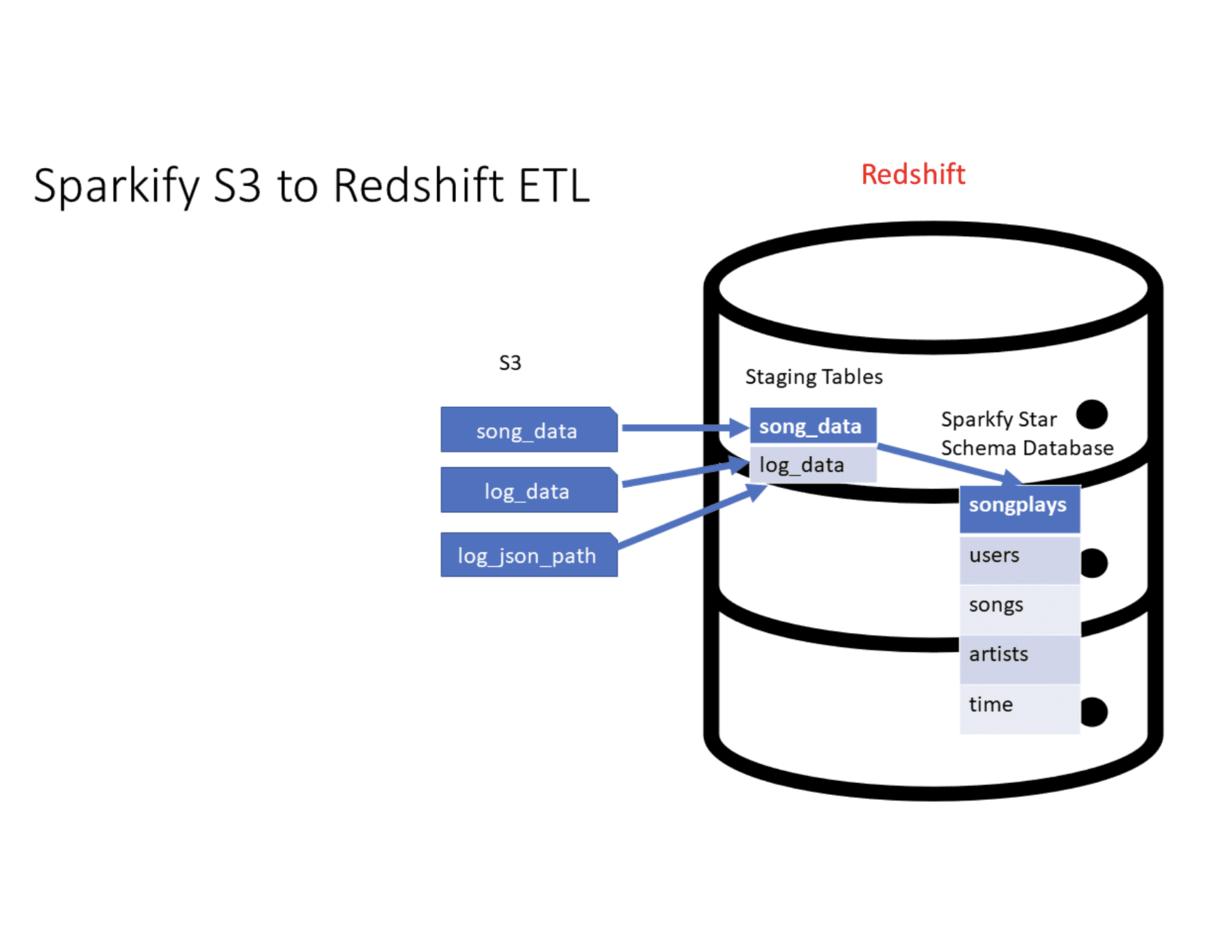
In response to Sparkify's growing user base and song library, this project implements an ETL pipeline on Amazon Redshift, enhancing analytics capabilities for the music streaming startup.
Publications
Through diligent research and thoughtful publications, we pave the way for knowledge to flourish and society to advance!
Malicious URL Classification Using Machine Learning Algorithms and Comparative Analysis
Published in : 3rd International Conference on Computational Intelligence & Informatics | Date: 29 Dec, 2020
The paper, titled "Malicious URL Classification Using Machine Learning Algorithms and Comparative Analysis", authored by Anshuman Sharma and Abha Thakral and published in 2020 in the field of Computer Science, explores the classification of internet traffic as malicious or non-malicious using machine learning algorithms.
The paper implements four popular machine learning classifiers: KNN, Naive Bayes, Decision Trees, and Random Forest, to classify internet traffic and compares their results based on accuracy scores. By leveraging these algorithms, the study aims to enhance the accuracy and efficiency of classifying internet traffic, thus contributing to improved cybersecurity measures.
Read more
MY ARTICLES AND BLOGS
I've wrapped up the 100 Days of Data Engineering Challenge!
Feel free to explore my Medium!!